Czy można badać przemysł muzyczny za pomocą nowoczesnych narzędzi big data? Oczywiście, że tak! Ale zamiast skupić się na liczbach sprzedaży czy osłuchów, można popatrzeć na bardziej socjalne aspekty, czyli… relacje międzyludzkie!
Big data wchodzi do mainstreamu
Pierwszy raz o potędze narzędzi big data społeczeństwo usłyszało w 2018 roku przy okazji afery „Facebook–Cambridge Analytica data scandal”. W skrócie – w 2018 roku ujawniono, że sztab Donalda Trumpa w trakcie kampanii prezydenckiej w 2016 r. korzystał z usług mało znanej firmy
Cambridge Analytica. Brytyjskie przedsiębiorstwo wykorzystywało pozyskiwane od Facebooka dane na temat nieświadomych użytkowników, a następnie przygotowywało specjalnie sprofilowane reklamy wyborcze.
I mimo że zbieranie i wykorzystywanie danych o nas działo się (i dzieje) na porządku dziennym, choćby kiedy robimy zakupy w Żabce, wywołało to ogromną dyskusję publiczną o wykorzystywaniu danych. Efekty widać było choćby w ostatnich wyborach do Europarlamentu, gdzie przy facebookowych reklamach pojawiały się informacje o finansowaniu kampanii. Po raz pierwszy z nowych narzędzi zaczęli korzystać też publicyści, którzy prezentowali ciekawe analizy.
Ten wpis został zainspirowany analizami londyńskiego Institute for Strategic Dialogue opublikowanymi przez Newsweek i oko.press, które dotyczyły siatki rosyjskich botów na polskojęzycznym twitterze. Efektem prac była specjalna mapa pokazujaca powiązania między poszczególnymi kontami:
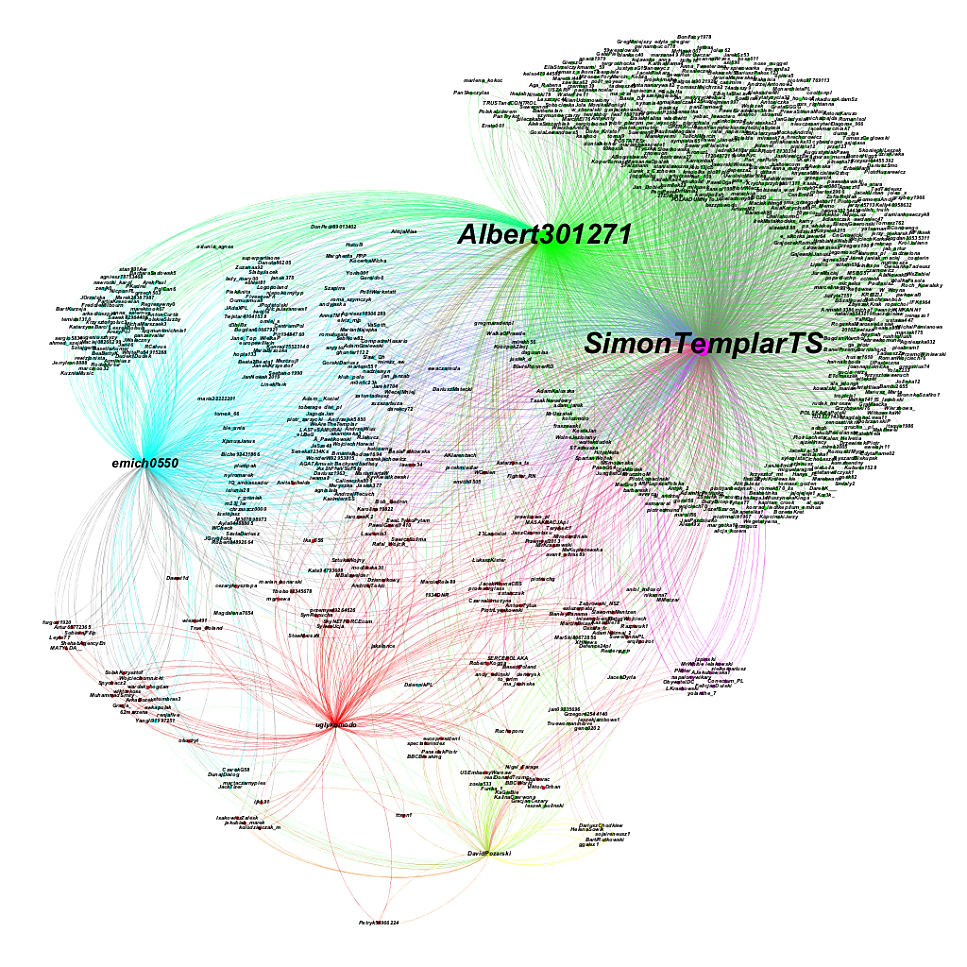
Pytanie jakie sobie postawiłem było następujące: czy można analogiczny sposób pokazać relacje międzyludzkie w przemyśle muzycznym? Odpowiedź brzmi: tak! O ile ma się do tego odpowiednie dane…
Dane źródłowe
Okazuje się, że takie informacje są w pewnym sensie zbierane. Organizacje zbiorowego zarządzania prawami autorskimi przechowują rejestracje utworów otrzymywane od związków zagranicznych (wymiana poprzez CIS-NET), wydawców muzycznych (rejestracje CWR) i samych twórców (rejestracje krajowe). Pojedyncza rejestracja zawiera szereg informacji koniecznych do wykonania repartycji wynagrodzeń autorskich – wykazy udziałowców i ich afiliacje z OZZ, części udziałowe w utworze, szczegóły dotyczące umów wydawniczych i subwydawniczych, numery utworów w różnych bazach danych itd. – jednak na potrzeby tego eksperymentu potrzeba nam „zaledwie” listy piosenek wraz z autorami.
Tutaj z pomocą przychodzi stowarzyszenie ASCAP, które zgodnie z prawem amerykańskim musi publikować zrzuty ze swojej aktywnej bazy utworowej ACE (ASCAP Clearance Express) – link do bazy znajdziecie tutaj.
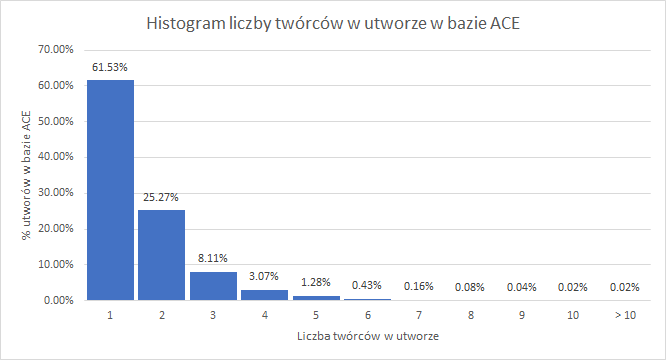
Samo pozyskanie kilku-gigabajtowego zestawu danych to dopiero początek. Na bazę ACE w chwili pobrania (04/06/2019) składało się:
- Liczba rekordów: 47 464 391
- Liczba utworów: 12 015 071
- Liczba twórców (IP name): 1 414 595
- Liczba wydawców (IP name): 217 603
Narzędzia
Oczywiście tak duży zbiór danych nie może być obrabiany ręcznie czy nawet w Excelu, dlatego jeśli ktoś chce pójść w moje ślady, musi poznać podstawy baz danych. Ja do tego celu wykorzystałem serwer Microsoftu, który dość dobrze przyjął (po wstępnym przetworzeniu) katalog ASCAPu.
Swoją drogą sama statystyka ACE jest niesłychanie ciekawa. Przykładowo średnio jedna piosenka napisana jest przez 1,60 osoby, co odbiega od standardowego „2-4” w przypadku muzyki popularnej z powodu bardzo dużej liczby utworów bibliotecznych z jednym twórcą.
Odpowiednio przygotowane dane analizowałem za pomocą ogólnodostępnych narzędzi napisanych w Pythonie – przede wszystkim networkx (więcej do poczytania tutaj https://networkx.github.io).
Efekty
Ponieważ było to moje pierwsze spotkanie z wielowymiarową analizą i grafami, nie spodziewałem się spektakularnych efektów. Główne wnioski:
- Liczba powiązań między autorami jest tak wielka, że przygotowanie dokładnej analizy relacji wymaga ogromnej mocy obliczeniowej. Z tego powodu bardziej opłaca się wizualizować tylko twórców, którzy nas interesują niż całą „sieć”.
- Relacje między twórcami są niezwykle zawiłe i skomplikowane, co powoduje, że praktycznie nie da się ich w pełni przedstawić w sposób czytelny na płaszczyźnie 2D. Oznacza to, że arbitralnie należy ustalać pewne progi powiązań.
Na potrzeby tego wpisu zrobiłem 3 wizualizacje.
- Analiza ogólna skupień twórców

Widoczne są charakterystyczne „zagęszczenia” sieci kompozytorów:
- Obszar „A” są to twórcy muzyki country związani ze środowiskiem Nashville (np. Ashley Gorley, Jon Nite)
- Obszar „B” – twórcy związani z muzyką reggae i wpływami kultury Jamajki (np. Miguel Orlando Collins, Christopher Birch)
- Obszar „C” – twórcy hip-hopowi (Christopher George Latore Wallace, Lil Wayne).
- Obszar „D” – luźna i rozproszona siatka twórców muzyki pop (Lady Gaga, Sia, Beyonce).
Doskonale widać, że twórcy country są bardzo hermetyczną grupą, z kolei muzycy popowi lubią współpracować z wieloma osobami.
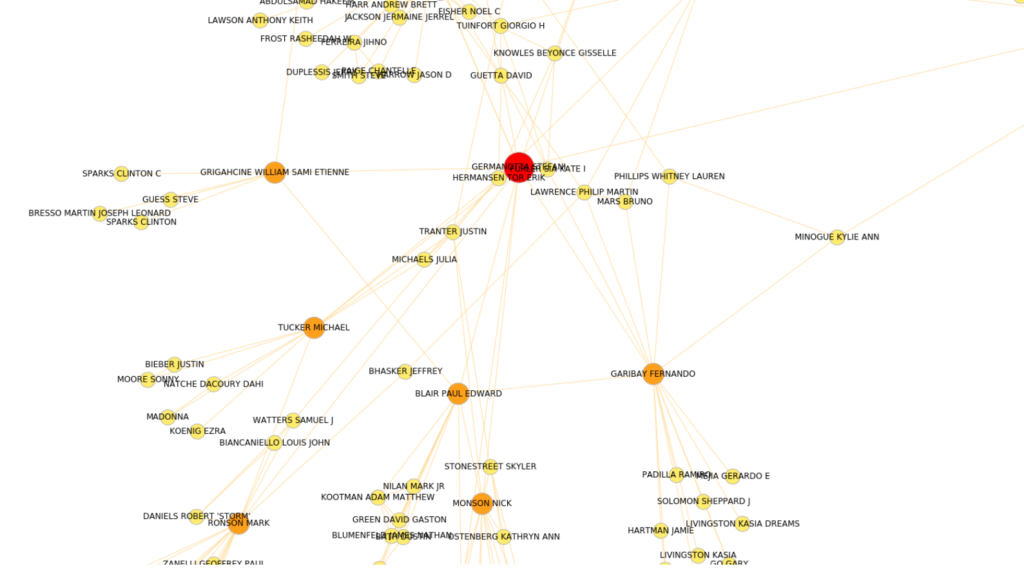
2. Analiza otoczenia konkretnych twórców
Dość ciekawe wyniki dała wizualizacja otoczenia konkretnych twórców. Ja na warsztat wziąłem Się i Lady Gagę. O ile w przypadku Sii okazało się, że to ona jest węzłem spinającym wszystkich twórców, to graf dla Gagi pokazał bardzo silny team kompozytorski skupiony wokół Hillary Lindsey – autorski country z którą Gaga pracowała przy okazji albumu „Joanne”.
Po kliknięciu możecie zobaczyć całe grafy, ale uwaga – są dość ciężkie (kilka MB)

Wnioski
Potencjalnych zastosowań takich analiz może być wiele, ale przede wszystkim powinny one zainteresować działy A&R, które niejednokrotnie bardzo szybko muszą zorientować się jak wygląda otoczenie twórcze danego autora.
Mnie nauczyło to jednak czegoś innego – w trakcie mojego researchu nikt nie wpadł na pomysł, aby dane ze stowarzyszeń autorskich prezentować w formie powyższych grafów. To pokazuje tylko jak wiele branża muzyczna może nauczyć się od innych gałęzi IT.