
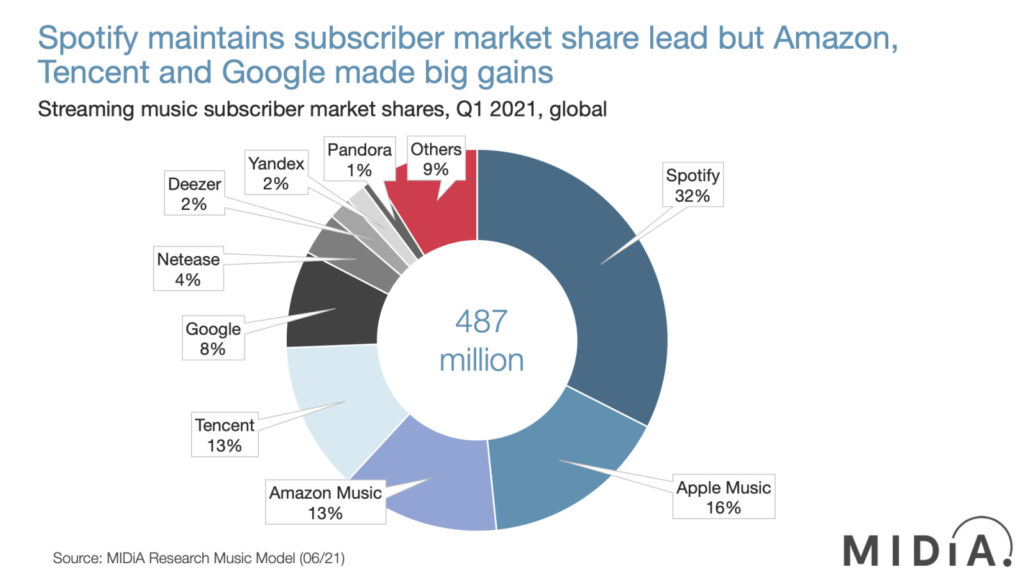
Spotify to obecnie najpopularniejszy, płatny serwis muzyczny na świecie, z którego korzysta 381 mln aktywnych użytkowników, z czego 172 mln to użytkownicy płatni, co przekłada się na ok. 32-procentowym udziałem w globalnym rynku dwukrotnie wyprzedzając Apple Music.
Nic dziwnego. Spotify wygrywa w praktycznie wszystkich rankingach serwisów muzycznych, a jednym z najczęstszych argumentów padających na korzyść szwedzkiej platformy są automatyczne rekomendacje muzyki. W najnowszym rankingu TechRadaru rekomendacje, na które składają się przede wszystkim Discover Weekly (wprowadzone w lipcu 2015) i Release Radar (sierpień 2016), wymieniane są najwyżej na liście zalet Spotify. Skąd Spotify wie, czego chcemy słuchać? Z pomocą przychodzi BaRT.
Jak działa algorytm Spotify?
Szczegółów tak naprawdę nie znamy, bo konkurencja Spotify patrzy 😉 Można się jednak domyśleć jak wygląda zaplecze playlist znając najpopularniejsze algorytmy rekomendacji stosowane w innych sektorach, np. e-commerce. Pomocny jest też artykuł, który w 2017 roku napisała Sophia Ciocca, programistka Spotify. Wiemy, że sercem rekomendacji Spotify jest BaRT, czyli Bandits for Recommendations as Treatments, który schematycznie wygląda następująco:
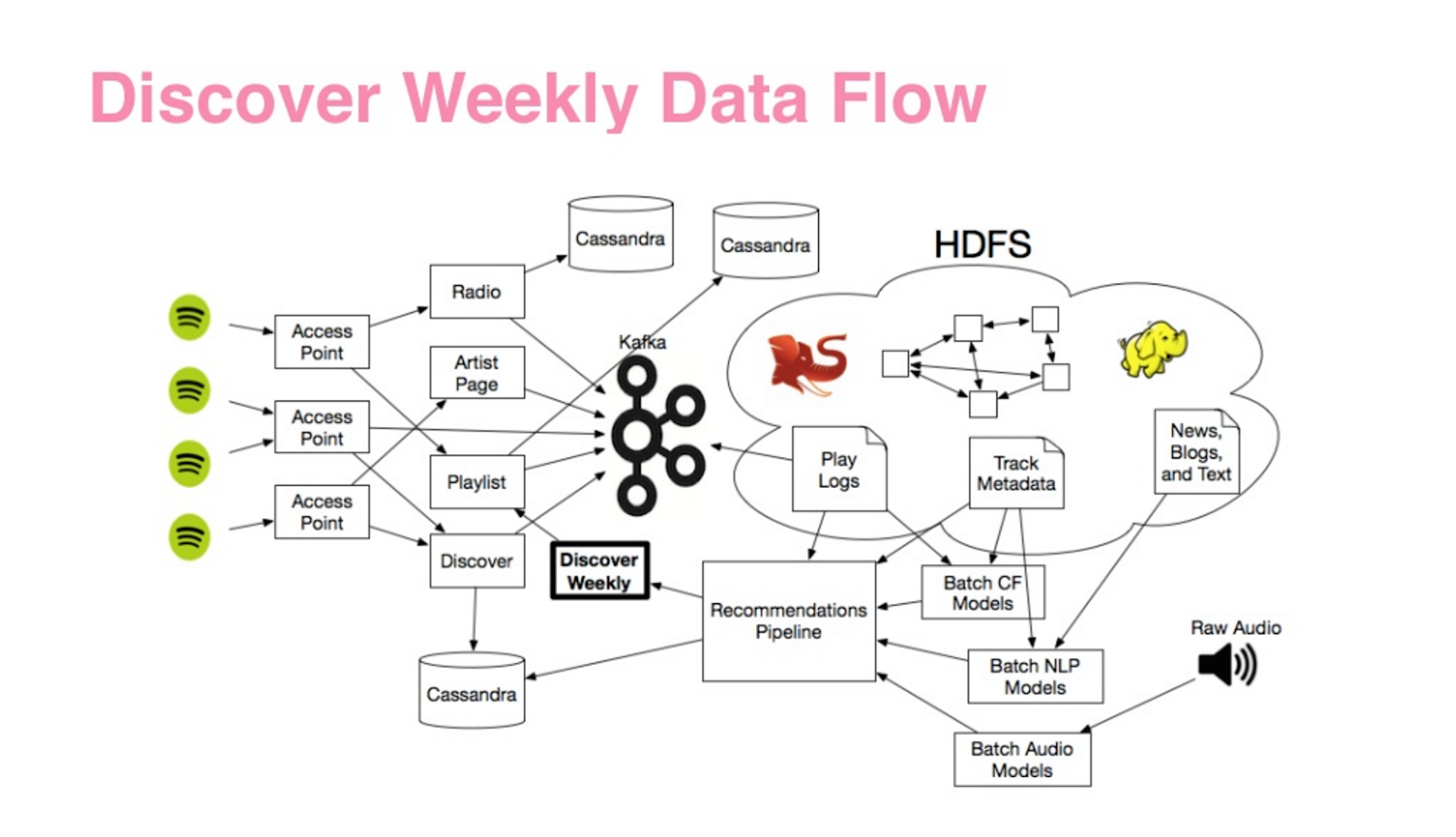
BaRT to bardzo rozbudowany system, który, co raczej nie jest zaskoczeniem, zbiera jak najwięcej danych, które potem służą do personalizacji treści (zgodnie ze złotą zasadą big data: „lepiej mieć niż nie mieć”). Będą to oczywiście dane o konsumpcji (co i jak słuchał dany użytkownik serwisu), metadane ale też treści „spoza” ekosystemu Spotify. Analiza takiej liczby bardzo różnorodnych i specyficznych danych nie jest zadaniem prostym, ale na pomoc przychodzą dwa, fundamentalne algorytmy.
Content-Based Filtering
Pierwszy z nich to Content-Based Filtering i polega na rekomendowaniu muzyki „podobnej” do tego, co wcześniej chętnie słuchaliśmy.
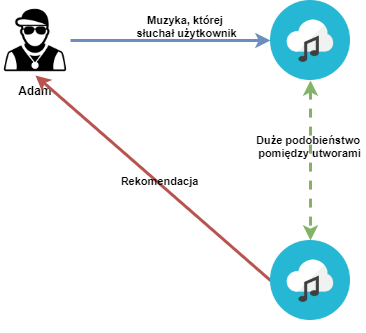
Żeby algorytm mógł zarekomendować podobną piosenkę do innych, potrzebne jest stworzenie miary (wskaźnika), który opisuje „stopień podobieństwa” (np. piosenka „A” i „B” są podobne w 45%, ale „A” i „C” już w 90%). I tutaj zderzamy się ze ścianą.
Proces interpretacji muzyki przez mózg człowieka jest zbyt skomplikowany, żeby dałoby się go „algorytmicznie” odtworzyć i powiedzieć, że dwa nagrania „brzmią podobnie” (zresztą takie pojęcie jest i tak bardzo subiektywne). Pierwsze kroki w tym kierunku zrobiła firma The Echo Nest, która nauczyła się mierzyć pewne cechy treści dźwiękowych: prostych takie jak tempo czy tonacja, ale też bardziej subiektywnych typu „acousticness” (prawdpodobieństwo, że utwór jest w aranżacji akustycznej), „danceability” (stopień, w jakim dane nagranie nadaje się do tańca), czy nawet „energy” (jak bardzo „energetyczny” jest dany utwór).
W 2014 roku The Echo Nest zostało przejęte przez Spotify, dzięki czemu tego typu informacje mogą być wykorzystywane przez BaRT. Każdy może sprawdzić parametry swojej ulubionej piosenki – Spotify udostępnia dane poprzez swoje API, do którego wpiętych jest wiele stron, na przykład Tunebeat.
Dopóki nie zrozumiemy lepiej tego jak nasze mózgi interpretują muzykę wyżej wymienione parametry będą tylko elementem wspomagającym, bo w przypadku tego algorytmu kluczową rolę odgrywają metadane. Najważniejszym i najbardziej oczywistym „elementem” łączącym różne piosenki jest przecież wykonawca i przypisany gatunek muzyczny, ale uwzględnione mogą być też takie informacje jak producent, autor i kompozytor, przypisany język, mood itd. Właśnie dlatego rzetelne uzupełnianie metryk produktów dostarczanych do streamingów jest kluczowe. Na tym etapie możliwa też jest analiza tekstów, czyli NLP (Natural Language Processing). Tutaj znowu na wejściu znajdą się metadane muzyczne, ale też też tekst piosenki czy wzmianki na temat utworu w serwisach społecznościowych.
Dzięki temu, że Content-Based Filtering bazuje na obiektywnych parametrach, które w pełni przypisuje komputer, może być stosowany nawet na utworach jeszcze nie opublikowanych. Właśnie dlatego idealnie nadaje się w przypadku rekomendacji nowości w dniu premiery – na przykład na personalizowanej playliście Release Radar.
W uproszczeniu działanie algorytmu opartego o content-Based Filtering w „Radarze premier” może wyglądać tak. Jeśli swoją premierę ma nowy utwór Adele, to automatycznie zostanie on zaklasyfikowany jako podobny do wszystkich piosenek, które:
- Do tej pory wydała Adele („łącznikiem” będzie ten sam wykonawca).
- Miały przypisany ten sam gatunek muzyczny („zaszyty” będzie w metadanych albo zostanie dodany na etapie tzw. „pitchu” do playlist)
- Mają zbliżone „audio features” – tempo, „akustyczność”, taneczność, energia itd.
Jeśli dany użytkownik w przeszłości często słuchał piosenek spełniających powyższe kryteria, jest duża szansa, ze nowy utwór pojawi się w piątek na Release Radar.
Collaborative filtering
Niestety, jak wcześniej wspomniałem, jak na razie nie potrafimy „komputerowo” interpretować muzyki. W wydaje mi się, że przez wiele lat się to nie zmieni, bo w grę wchodzi nie tylko to jak mózg ludzki przetwarza dźwięk, ale też cechy osobiste słuchacza i kontekst kulturowy (trudno wyobrazić sobie, że obwieszony łańcuchami byczek z siłowni posłucha nowego singla Britney Spears…). Informatyka znalazła i na to sposób, a mianowicie collaborative filtering.
Ogólna zasada jest bardzo prosta – algorytm stara się kojarzyć ze sobą użytkowników, którzy słuchali podobnej muzyki („muzycznych bliźniaków) a następnie prezentować utwory, które słuchała jedna osoba a druga nie. Możliwe jest to dzięki temu, że, choć nie lubimy o sobie tak myśleć, to wcale nie jesteśmy wyjątkowi i osób o podobnych upodobaniach (choćby muzycznych) jest zdecydowanie więcej niż nam się może wydawać.
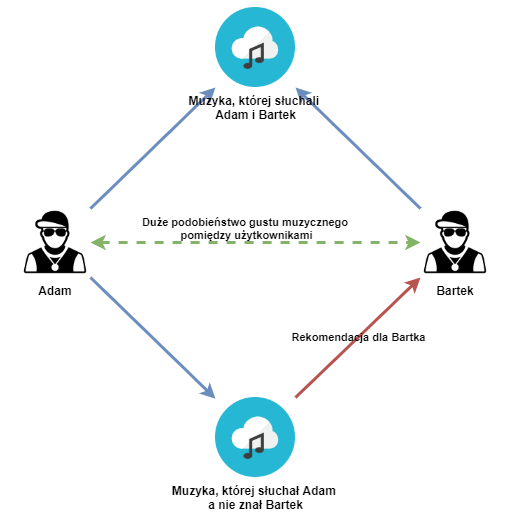
Tego typu rekomendację mają ogromne znaczenie nie tylko w przypadku algorytmów muzycznych, ale stosują je zarówno serwisy VOD, social media pozycjonując treści ale też sklepy internetowe czy portale informacyjne. Wadą tego rozwiązania jest to, że wymaga „zebrania” odpowiednio dużego zasobu danych, tak więc collaborative filtering nie zadziała w dniu premiery, za to świetnie sprawdzi się na playliście Discover Weekly.
A w praktyce… to nie takie proste
Co prawda same algorytmy są dość proste, praktyka już taka nie jest, o czym świadczy 837 mln euro wydanych w 2020 roku przez Spotify na R&D (Research and development); dla porównania Spotify ze sprzedaży reklam zarobiło w tym okresie 745 mln EUR. Po pierwsze BaRT jest na tyle rozbudowanym serwisem, że korzysta jednocześnie z obu algorytmów na raz i kilku innych, o których nie wspominałem.
Po drugie, same algorytmy wymagają tak zwanego „skalibrowania”. Na przykład w przypadku Content-Based Filteringu porównujemy wiele parametrów piosenki jednocześnie. Co jest ważniejsze – zbliżone tempo czy parametr „acousticness”? A może dla piosenek akustycznych podobne tempo ma większe znaczenie niż elektronicznych? Co to w ogóle znaczy „podobne”? Tutaj, jak i na pewno w innych miejscach BaRTa, pomocne są algorytmy machine learning, które dosłownie „uczą się” co jest ważne a co mniej istotne.
Po trzecie, samo zbudowanie systemu, który działa w trybie operacyjnym jest bardzo trudnym zadaniem – nikt nie chce, aby „super precyzyjny” algorytm „Release Radar” pokazywał nam nowości z opóźnieniem kilku miesięcy, bo tyle zajmie przeliczenie danych dla wszystkich 381 milionów użytkowników!
Rekomendacje muzyczne – co dalej?
Można się zastanowić też przez chwilę jak serwisy streamingowe będą starały się ulepszać swoje algorytmy rekomendacji treści. Możliwości jest kilka
Pewne jest to, że serwisy streamingowe będą starały się zbierać coraz większą liczbę nowych danych. Tutaj na prowadzenie wychodzi YouTube, które dysponuje ogromnymi zasobami Google. Największa wyszukiwarka na świecie w październiku 2020 uruchomiła opcję „Hum to search”, która działa jak Shazam a dodatkowo rozpoznaję muzykę ze śpiewu czy mruczenia. Prawie w tym samym czasie samo YouTube uruchomiło „swojego TikToka” czyli Shorts, a nie zdradzę raczej wielkiej tajemnicy, że to właśnie krótkie formy wideo są obecnie najważniejszym elementem jeśli chodzi o szukanie przyszłych hitów.
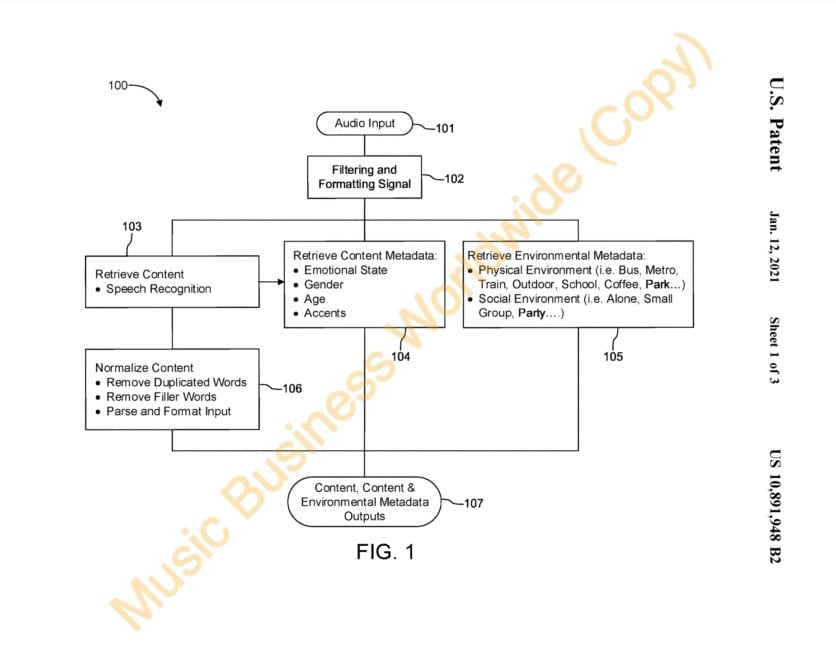
Spotify stara się nie zostawać w tyle rejestrując patent na monitorowanie „dźwięków tła”, w którym znajduje się użytkownik, a następnie ekstrakcję takich cech jak fizyczne cechy otoczenia (komunikacja miejska, szkoła, park itd.), społeczne cechy otoczenia (czy użytkownik jest sam czy w grupie ludzi), ale też informacje o samym użytkowniku (płeć, wiek, emocje). Wszystko po to, aby rekomendacje były jeszcze lepsze.
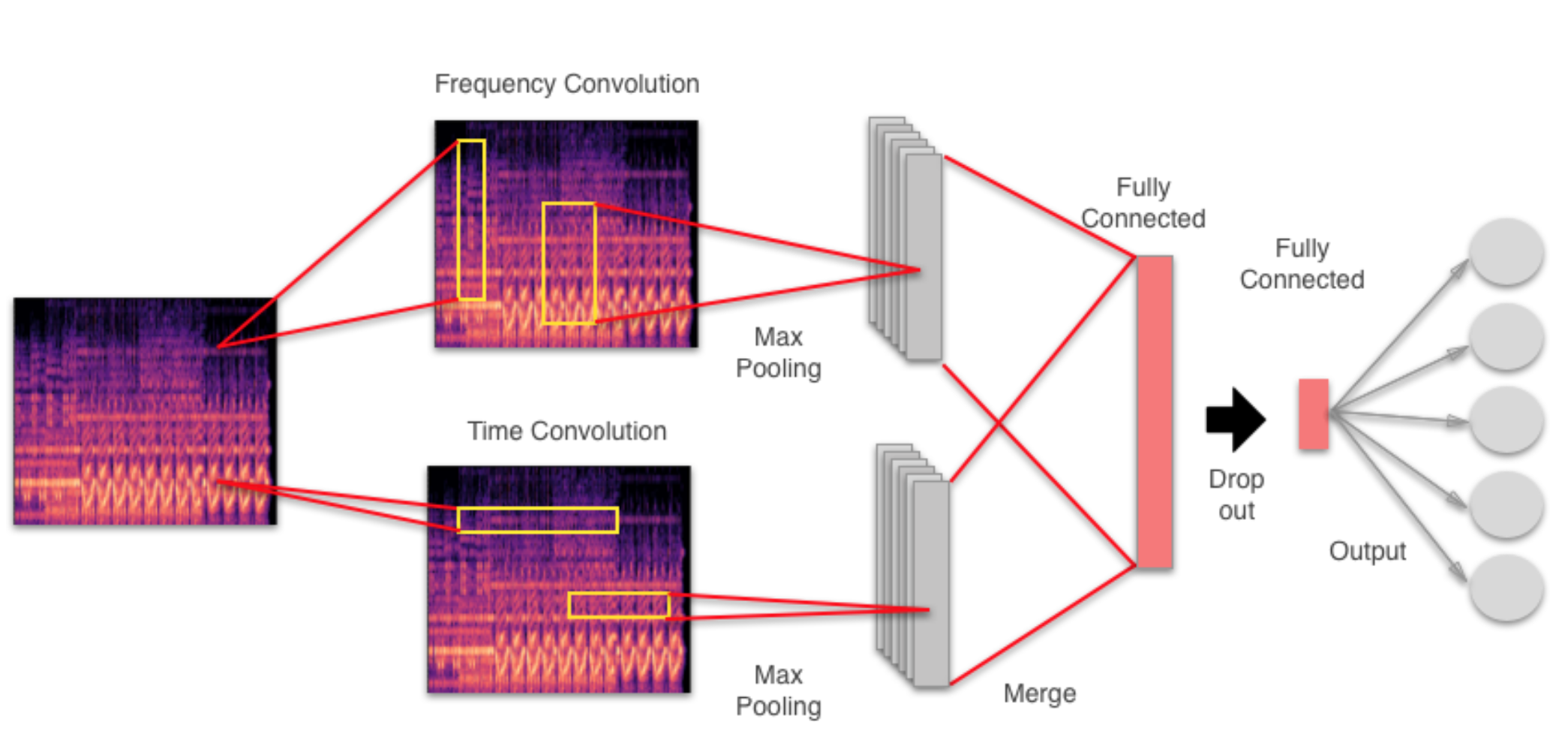
Na pewno w dalszym ciągu rozwijane będą technologie analizy materiału dźwiękowego (audio features) w oparciu uczenie maszynowe, co jest tematem bardzo świeżym i większość ważniejszych publikacji pochodzi z ostatnich 3 lat. Na przykład obecnie bardzo popularnym tematem jest klasyfikacja gatunków muzycznych w oparciu o splotowe sieci neuronowe. Do tej pory tego typu sieci znalazły szerokie zastosowanie w analizie zdjęć. Okazuje się, że muzykę również można analizować w ten sposób – wystarczy przedstawiać ją w dziedzinie częstotliwości, czyli spektrogramów. A najciekawsze w tym wszystkim jest to, że taką sieć właściwie może zrobić każdy – w internecie są gotowe kody źródłowe wraz ze szczegółowym opisem, np. tutaj
Być może w niedalekiej przyszłości każdy będzie miał „swoją sieć”, która nauczona doświadczeniem milionów użytkowników będzie dopasowywała się do gustu pojedynczego użytkownika i na podstawie samych parametrów dźwiękowych będzie mogła rekomendować muzykę. Z jednej strony brzmi to super, a z drugiej może się okazać, że wielka machina pośredników i promotorów przestanie być potrzebna. I może brzmi to bardzo futurystycznie, ale patrząc na tempo prac taki scenariusz jest jak najbardziej możliwy już w kolejnej dekadzie. Czy to już pora zmieniać pracę?