
Na początku lutego CISAC ogłosił, że rozpoczął współpracę z firmą Spanish Point Technologies nad rozbudową back-office dla standardu ISWC. Jego zadaniem ma być zwiększenie użycia kodów ISWC (uniwersalnych numerów utworów) przez serwisy streamingowe, co ułatwi rozpoznawanie repertuaru przez organizacje zbiorowego zarządzania i wydawców muzycznych. Dlaczego jest to takie ważne wyjaśnię na końcu.
Matching
Jednym z podstawowych problemów z jakimi zmaga się przemysł muzyczny, a w szczególności ten zajmujący się prawami autorskimi jest matching. Formalnie matching można określić jako przypisanie elementom jednego zbioru (UP) odpowiadających elementów zbioru referencyjnego (W).
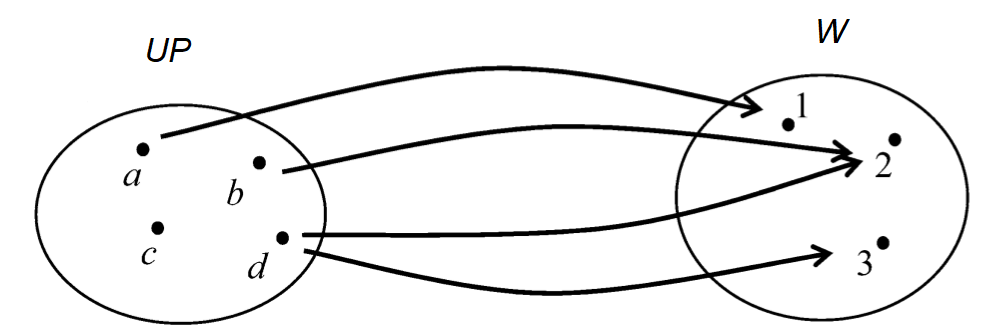
Dla przykładu: wyobraźmy sobie, że mamy listę piosenek UP (np. załącznik do faktury z serwisu streamingowego). Matching polegał będzie w tym przypadku na przypisanie każdej z linii pliku UP (na wykresie – literka) numeru piosenki ze zweryfikowanej bazy referencyjnej W.
Zadanie wydaje się raczej proste, ale tylko w sytuacji kiedy baza referencyjna i lista utworów niezidentifykowanych są niewielkie – wtedy można zrobić to ręcznie, czyli wykonać tzw. manual matching. W praktyce są to jednak zbiory rzędu kilkudziesięciu milionów (!) rekordów na liście zewnętrznej i kilku milionów w bazie referencyjnej, co praktycznie wyklucza możliwość wyłącznie ręcznej pracy i zmusza stowarzyszenia i wydawców do tworzenia baz danych.
Klasyczne relacyjne bazy danych potrafią niesłychanie szybko łączyć ze sobą duże zbiory danych (tablice). Problem w tym, że to łączenie odbywa się za pomocą klucza, który musi być identyczny w obu zbiorach danych (tablicach). Czym będzie klucz w przypadku list utworów? Najbardziej pierwotnym będzie kombinacja tytułu i listy twórców (których może być kilku!). I tu zaczynają się schody…
Algorytmu string metrics – serce fuzzy matchingu
Rzadko kiedy dane w liście utworów nierozpoznane i w bazie referencyjnej są takie same. Powiem więcej – prawie zawsze się różnią i występują tak naprawdę wszystkie możliwe błędy jakie można sobie wyobrazić. Wymaga to więc matchowania niedokładnego, czyli fuzzy matchingu. Sercem fuzzy matchingu są algorytmy String metrics, których typów i modyfikacji jest baaardzo dużo (na Wikipedii jest aż 19 a ja i tak używam zupełnie innego, co świadczy o możliwości bardzo indywidualnego podejścia). Ich zadaniem jest wyliczenie wskaźnika podobieństwa (na potrzeby tego wpisu oznaczam go jako S) pomiędzy dwoma tekstami (np. tytułami piosenek). „Wystarczy” więc wybrać tytuły najbardziej podobne (powyżej pewnego minimalnego progu), żeby połączyć dwa rekordy.
Niestety, nie jest to wcale proste. Wyobraźmy sobie, że w bazie referencyjnej istnieją tytuły: „Love Song” i „The Love Song 2” a na liście szukanej mamy „The Love Song„. Każdy prosty algorytm wskaże, że „The Love Song” odpowiada referencyjny rekord „The Love Song 2”, co jest oczywiście nieprawdą, bo dwójka sugeruje, że jest to inna, nowa wersja, a obecność przedimka „the” można tak naprawdę zignorować.
Bardziej zaawansowany algorytm porównywać będzie więc czy w tytule występują liczby (jeśli tak – to czy takie same) oraz ignorować będzie interpunkcję i przedimki oraz inne słowa-klucze takie jak np. „cues”. Ale zaraz po tym trzeba uwzględnić – obok cyfr arabskich też rzymskie. O innych wersjach świadczyć może dopisek „remix”. Dopisek „feat.” czasem będzie sugerował inną wersję (np. w Despacito) , czasem nie. Tytuły w nawiasach czasem mogą być zignorowane, czasem stanowią integralną część tytułu.
A analiza tytułów to dopiero początek. W bazach międzynarodowych OZZ utworów krajowych o tytule „Love” jest ponad 6 tys, więc odnalezienie właściwego rekordu wymaga oczywiście skorzystania z informacji o autorach. Jest to zadanie naprawdę bardzo skomplikowane, bo wchodzą tutaj kwestie: różnych separatorów (o ile są), różnych kolejności zapisów imion (pełnych lub skróconych) i nazwisk czy występowania pseudonimów (zarejestrowanych lub nie w bazie IPI / ISNI). Do tego dochodzi oczywiście kwestia literówek (przy jakim poziomie podobieństwa tekstów można mówić o matchu w przypadku imienia, nazwiska oraz całości nazwy?) i ewidentnych błędów (jako twórca wpisany jest wykonawca lub nazwa wytwórni muzycznej).
To jednak nie koniec – nie zawsze informacja o autorach jest dostępna. O ile w XVIII czy XIX wieku świat muzyki zorientowany był wokół kompozytorów (utwory Mozarta, Bacha, Chopina itd.), to po wynalezieniu fonografu mówiąc o piosence „Beyonce” nie mamy na myśli utworu napisanego przez panią Knowles tylko przez nią wykonywanego. Stąd zbieranie i analizowanie informacji o wykonawcach – mimo że nie są „stale” połączeni z utworem – jest kluczowe. Tak samo jak kluczowe zbieranie jest informacji o różnych identyfikatorach, w szczególności kodów ISRC, które potrafi bardzo zaoszczędzić obliczeń (i czasu!) o czym dalej.
Jedna linia – wiele dopasowań
Co więcej – nawet gdybyśmy spisali i zaimplementowali wszystkie zasady rozpoznawania, okazałoby się, że czasem nasz algorytm dla jednego utworu odnajduje kilka rekordów w bazie referencyjnej (multiple matches). W takiej sytuacji konieczne jest dodanie do algorytmu automatchingu reguł hierarchii łączenia rekordów. Najprostszy (a mimo to wcale nie prosty!) zestaw reguł może wyglądać tak (opis słowny):
- Dla analizowanego utworu UP znajdź w bazie referencyjnej rekordy W, których (1) podobieństwo S tytułów głównych W(OT) lub dodatkowych W(AT) do tytułu UP(OT) jest większe niż 80% oraz (2) tytuły nie wskazują na różne wersje oraz (3) co najmniej jeden autor rekordu UP(IP) jest taki jak autor W(IP). Jeśli liczba znalezionych rekordów UP=>W > 1, przejdź do punktu 2
- Dla wszystkich rekordów UP => W z punktu 1 wybierz te, które (1) są utworami oryginalnymi lub są (2) opracowaniami i rozpoznani twórcy UP(IP) są w rejestracji W subautorami. Jeśli liczba znalezionych rekordów UP=>W > 1, przejdź do punktu 3.
- Dla wszystkich rekordów UP => W z punktu 2 oblicz liczbę rozpoznanych autorów IP i wyznacz maksimum. Jeśli istnieje więcej niż 1 rekord z maksymalną liczba rozpoznań IP, przejdź do punktu 4.
- Dla wszystkich rekordów UP => W z punktu 3 oblicz maksymalne podobieństwo tytułów Smax = max{S[UP(OT),W(OT)]; S[UP(OT),W(OT)]}. Jeśli istnieje więcej niż 1 rekord z takim samym Smax, przejdź do punktu 5.
- Dla wszystkich rekordów UP => W z punktu 4 oblicz maksymalne podobieństwo tytułów głównych Sot = S[UP(OT),W(OT)]. Jeśli istnieje więcej niż 1 rekord z takim samym Sot, utwór oznaczany jest flagą „do manualnego rozpoznania”.
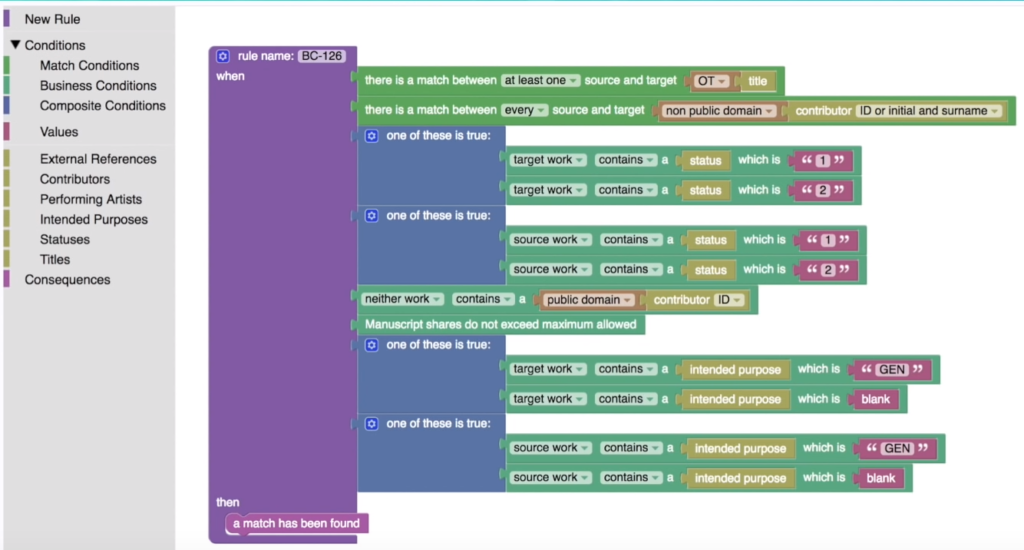
Bardziej zaawansowane systemy umożliwiają tworzenie elastycznych reguł – w zależności od celu i danych źródłowych (inaczej wygląda matchowanie list z rozliczeń a inaczej na potrzeby łączenia rejestracji utworów). Przykładowo, ICE Services posiada specjalny panel do graficznego tworzenia takich reguł co umożliwia zwykłym użytkownikom (nie-programistom) dowolne modyfikowanie zasad łączenia piosenek:
Wydajność
Nawet taki bardzo pobieżny opis problemu pokazuje, że potencjalny dobry system do automatchowania będzie zarówno bardzo rozbudowany jak i jednocześnie elastyczny. To jednak nie koniec, bo tak naprawdę największym wyzwaniem będzie zaprojektowanie aplikacji, która nie tylko spełnia wszystkie powyższe warunki „logistyczne”, ale też działa akceptowalnie szybko – czyli cechuje się wysoką wydajnością i skalowalnością. I nie jest to kwestia dobrych zasobów sprzętowych, ale optymalizacji algorytmów – faktem jest, że programistą może być każdy (wystarczy stackoverflow), ale napisanie dobrze zoptymalizowanego kodu to sztuka porównywalna z komponowaniem muzyki.
{kind=link}
Jak się okazuje, najbogatsze stowarzyszenia na świecie (PRS, STIM i GEMA, która wniosła do ICE moduły back-office’owe – „MAX” do matchowania i „LION” to zarządzania procesem licencjonowania) zdecydowały się na współpracę, co tylko świadczy o tym jak, trudny to proces. Niestety, mniej zamożne OZZ nie mogą pozwolić sobie na dołączenie do ICE, a nowe zasady licencjonowania muzyki w UE wymuszają na OZZ „wyszukiwanie” swojego repertuaru w milionowych, comiesięcznych zrzutach danych.
Zacznijmy od początku, czyli… od serwisów streamingowych
I tutaj pojawił się pomysł, który CISAC zrealizuje razem z Spanish Point Technologies – centralne rozpoznawanie repertuaru już na poziomie serwisów muzycznych.Projekt polegać ma na zbudowaniu standardu automatchowania na bazie technologii SPT przesyłania do serwisów streamingowych notyfikacji o istniejących kodach ISWC w bazie Central Search Index (CSI) i Musical Work Information (MWI) zbudowanej przez FastTrack. Jak czytamy na stronie firmy, ich „Matching Engine” jest wstanie matchować 30 tys. utworów na minutę przy możliwych 60 różnych łatwych do zmiany parametrach konfiguracyjnych.
W ten sposób stowarzyszenia przy wyszukiwaniu swojego repertuaru korzystać będą ze wskazanych wcześniej kodów ISWC, co znacząco odciąży ich systemy, bo wymagać będzie jedynie weryfikację, czy przypisany numer nie jest błędny. Oczywiście nie rozwiązuje to wszystkich problemów, bo matchowanie to tylko pierwszy krok do rozliczenia tantiem. Niemniej jednak jest to ważny krok w kierunku szybszego i dokładniejszego rozliczania wynagrodzeń dla autorów za wykorzystanie ich muzyki w internecie, które, jak pokazują raporty, rośnie w ekspresowym tempie. O tym jak bardzo ekspresowym w Polsce oficjalnie dowiemy się około w najbliższych tygodniach, jednak wstępne wyniki są bardzo pozytywne.
O pozostałych problemach tej części biznesu muzycznego, które nawet nie są w połowie rozwiązane postaram się napisać niebawem. Jeśli nie chcesz tego przegapić – dodaj się do newslettera:http://popruntheworld.pl/newsletter/
Pingback: Dlaczego utwór powinien mieć rozsądny tytuł – POPRUNTHEWORLD()