
fot. Flickr
Za początek branży fonograficznej uznaje się 1878 rok, kiedy Edison opatentował fonograf – pierwsze szeroko rozpowszechnione urządzenie do utrwalania i odtwarzania dźwięku. Od tego czasu przemysł muzyczny zmienił się nie do poznania, a motorem napędowym była, jest i z pewnością będzie technologia. Co warto obserwować? W co inwestować? Co rozwijać, aby być krok do przodu na rynku? Postaram się odpowiedzieć na te pytania w mini-cyklu „New Tech w muzyce”. W tym wpisie na ruszt idzie big data i sztuczna inteligencja.
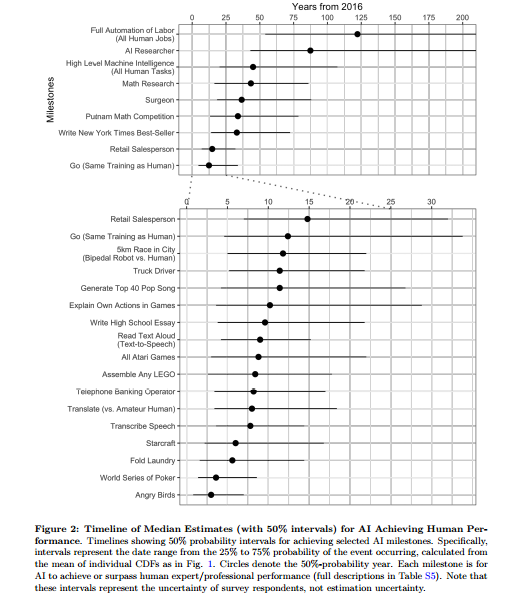
W ubiegłym tygodniu piątka naukowców – Katja Grace, John Salvatier , Allan Dafoe, Baobao Zhang i Owain Evans – z Oxfordu i Yale University opublikowała wyniki ankiety dotyczącej sztucznej inteligencji. Badanie obejmowało 352 uczonych, którzy w 2015 roku brali udział w konferencjach poświęconych artificial intelligence. Wśród pytań znalazło się jedno dotyczące muzyki:
Za ile lat (licząc od 2016 roku) AI będzie wstanie skomponować na tyle dobrą piosenkę, aby mogła dotrzeć do Top 40 USA (system powinien wygenerować gotowy plik audio)?
Zdaniem naukowców, którzy udzielili odpowiedzi (38), technologia osiągnie wymagany poziom ok. 2027 roku – mediana głosów z ankiety wyniosła 11,4 lata, przy czym rozrzut wyniósł od ok. 4 (2020 rok) do ok. 26 lat (2042 r.). Wydaje się, że jak na razie muzycy mogą spać spokojnie i kwestią kilku dekad może być generowanie spersonalizowanej muzyki „na życzenie”. Sztuczna inteligencja może jednak zawitać szybciej pod strzechy… a właściwie już dawno to zrobiła. Zanim to, historia, która da Wam nieco do myślenia.
Nastolatka, nieświadomy ojciec i bigdata
W 2012 roku Forbes opisał historię amerykańskiej nastolatki, jej ojca i sklepu Target. Ojciec dziewczyny zrobił wielką awanturę kierownikowi sklepu, ponieważ jego nieletnia córka zaczęła dostawać kupony promocyjne na akcesoria dla niemowlaków. Kierownik go przeprosił, jednak szybko okazało się, że… dziewczyna faktycznie spodziewała się dziecka.
Jak to możliwe, że sklep wiedział o ciąży córki szybciej niż ojciec? Wszystko przez system kart lojalnościowych i analizę danych. Target, jak wszystkie duże sklepy, zbiera informacje o zakupach swoich klientów, a następnie – wykorzystując odpowiednie narzędzia analityczne – stara się przewidzieć czym zainteresowany będzie dany kupujący. Sklep analizując koszyki zakupowe nastolatki i porównując je z historycznymi transakcjami innych klientek doszedł do wniosku, że jeśli ktoś przez kilka tygodni kupuje witaminy i suplementy diety, potem bezzapachowy żel do ciała, to w 87% jest w ciąży, więc naturalnym krokiem będzie zaoferowanie pieluch.
Spersonalizowane oferty dużych sklepów to klasyczny przykład analizy big data. Za Wikipedią: Big data – termin odnoszący się do dużych, zmiennych i różnorodnych zbiorów danych, których przetwarzanie i analiza jest trudna ale jednocześnie wartościowa, ponieważ może prowadzić do zdobycia nowej wiedzy. Historia zakupów jest tutaj idealnym zbiorem danych do dalszej obróbki. Na wstępie mamy ID klienta, ID produktu i stempel czasu zakupów. Informację o czasie łatwo rozszerzyć o dane takie jak pora dnia czy dzień tygodnia, a to już pozwala wyciągać nowe wnioski (W jakim dniu tygodnia klienci najchętniej kupują produkt X?). ID produktu można sprzęgnąć z bazą produktów i uzyskać dane o cenach, kategoriach i grupach produktów (Zamiast banana czikita mamy informację, że to po prostu banan, czyli owoc – dla nas to oczywiste, jednak kiedy operuje się na miliardach rekordów, jest to istotne). Klient zakładając kartę lojalnościową podaje zazwyczaj swój kod pocztowy, płeć, być może również wiek – to koleje dane. Ba, na podstawie daty zakupów, do bazy danych można dołączyć zewnętrze informacje o pogodzie archiwalnej i w ten sposób śledzić zależności zakupów wody mineralnej od temperatury! To daje już bardzo rozbudowany (mówiąc ładniej: wielowymiarowy) zbiór danych. Jeśli ten zbiór posiada dodatkowo dużo rekordów (czyli pojedynczych zakupów – w sieci supermarketów to nie problem), to idealną bazę pod analizę big data!
Discover weekly
Czy w muzyce zastosowanie analizy big data ma szanse powodzenia? Już ma i stawiam, że regularnie z tych osiągnięć korzystacie. Najlepszym przykładem są zbierające, niezależnie od gustu muzycznego, pochwały listy Spotify „Discover weekly” Spotify, która bazuje na dokładnie takich samych mechanizmach jak opisane wyżej. Zamiast listy sprzedanych produktów analizowane są playlisty odtworzonych piosenek. Zasada algorytmu jest prosta: dla każdego użytkownika (jest ich ponad 100 mln!) Spotify wyszukuje osób, które słuchają bardzo podobnej muzyki – przykładowo, jeśli 80% Top20 najchętniej słuchanych utworów jest takie same. Następnie, z playlist wybranych osób algorytm serwisu wybiera te piosenki, których użytkownik nigdy nie słuchał i sortuje się je od największej popularności w grupie do najmniejszej; z tego Top25 może być uznane za playliste „Odkryj w tym tygodniu”.
Oczywiście, można zastanawiać się, czy wymieniony algorytm jest optymalny i ma jak najmniejszy błąd – kto powiedział, że musimy wziąć Top20 najchętniej słuchanych utworów? Może lepsze wyniki dałoby Top50 z podobieństwem 60%? Ten problem można rozwiązać sprawdzając wszystkie możliwe kombinacje, ale najlepiej w tym zadaniu sprawdzi się szeroko pojęte uczenie maszynowe – o nim dalej.
Uczenie maszynowe
O innym zastosowaniu analizy big data usłyszeliśmy również od Spotify kilka dni temu. Biuro prasowe szwedzkiej platformy wytypowało 15 utworów, które mogą stać się hitami lata 2017. W komunikacie czytamy:
Podczas tworzenia listy letnich przebojów, Spotify skorzystało z wiedzy swoich ekspertów w temacie gatunków i trendów, przeanalizowało dane streamingowe, jednocześnie biorąc pod uwagę takie czynniki jak pozycja piosenki na listach przebojów, na kluczowych playlistach Spotify oraz jak dany utwór radzi sobie z upływem czasu. Aby stworzyć tę idealną ścieżkę dźwiękową na tegoroczne lato, zespół Spotify wziął również pod uwagę popularność utworów w mediach społecznościowych.
Innymi słowy: serwis ma oczywiście dzienna historię odtworzeń wszystkich utworów z ponad 40-milionowej biblioteki. Do tego jak widać przechowuje historyczne informacje o pozycjach na playlistach (zapewne z uwzględnieniem liczby obserwujących). Na podstawie takiego przepastnego zbioru danych, z uwzględnieniem danych social media (na tym bazują listy „viral”) Spotify prognozuje zmiany liczby odtworzeń każdej z piosenek, a następnie 15 z największą, sumaryczną liczbą streamów od czerwca do sierpnia.
Tym razem zaproponowanie algorytmu przewidującego odtworzenia nie jest tak trywialne jak w przypadku „discover weekly” (trudno „zgadnąć” jak wykorzystywać wszystkie parametry), jednak rozwiązanie może przynieść nam szeroko pojęty dział uczenia maszynowego. Nie wdając się zbytnio szczegóły – machine learning (zajmujące się sztuczną inteligencją) stara się dopasowywać parametry algorytmów (takiego jak prognozowanie popularności piosenki w czasie) poprzez porównywanie historycznych danych wejściowych i wyjściowych. Przykładowo: parametrami wejściowymi algorytmu są odtworzenia z ostatnich 30 dni, parametrem wyjściowym – odtworzenie w dniu kolejnym („jutro”). Brzmi to bardzo skomplikowanie, ale implementacja (czyli zaprogramowanie) jest bardzo proste, szczególnie, że istnieje szereg gotowych narzędzi – jeśli chcecie się pobawić, nie ma problemu!
Chatboty, A&R i inne
Możliwości big data i AI nie kończą się jednak na personalizacji playlist i prognozowaniu przyszłych hitów jak robi to wspomniany Spotify (czy znana wszystkim aplikacja Shazam). Pod koniec 2016 roku hitem serwisów społecznościowych były chatboty, które zwiększały zaangażowanie fanów w kampaniach promocyjnych materiałów Bastille czy Olly’ego Mursa.
Duże wytwórnie powoli zaprzęgają algorytmy uczenia maszynowego do odkrywania nowych talentów. Póki co doświadczony headhunter jest nie do zastąpienia, ale jego możliwości mogą być jeszcze większe, jeśli zacznie wspomagać się danymi z pulpitu managerskiego zbierającego dane z social media czy serwisów strumieniowych. Jeśli jakiś wykonawca budzi duże zainteresowanie na Facebooku, obserwuje się raptowny wzrost obserwujących na YouTube oraz liczby streamów w Spotify a jednocześnie nie ma kontraktu fonograficznego – warto rozpocząć z nim rozmowy.
To jednak dopiero początek możliwości! Nadal brakującym ogniwem między muzyką a słuchaczem jest algorytm, który jest wstanie interpretować dźwięki tak jak robi to człowiek. To jednak pieśń przyszłości (i temat na kolejny wpis!).
Z tego tekstu zapamiętajcie: big data i sztuczna inteligencja to najszybciej rozwijający się dział przemysłu muzycznego. Aktualnie narzędzia wykorzystywane są do:
- Personalizacji playlist („Discover weekly”, „Daily mix”, itd.)
- Prognozowania przyszłych hitów („Future Hits” Shazam),
- Zwiększanie zaangażowania fanów poprzez chatboty.
- Odkrywanie nowych talentów przez działy A&R.
- Komponowanie utworów muzycznych – jak na razie jedynie zapisów nutowych, a nie gotowych plików audio.