Sukces przemysłu kreatywnego w akceptacji przez Unię Europejską projektu dyrektywy o prawie autorskim będzie miała kilka ważnych konsekwencji. Jedną z nich jest obowiązek (w przypadku dużych serwisów) implementacji systemów do zarządzania prawami do treści – takich jak Content ID YouTube/Google. Ja postanowiłem sprawdzić jakie są możliwości jego serca – algorytmu accoustic fingerprinting implementując jego własną realizację!
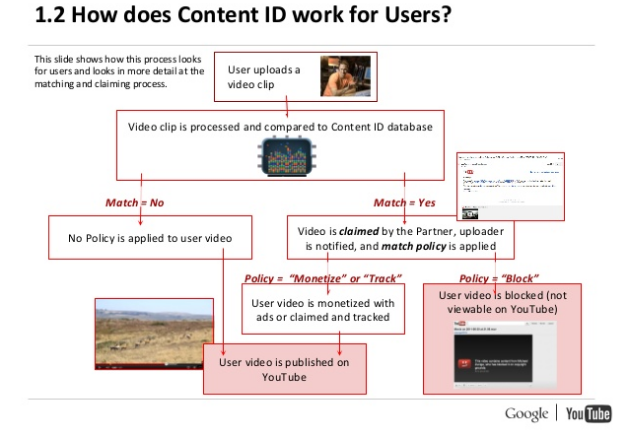
Pod adresem Content ID padło już wiele negatywnych stwierdzeń, choć trzeba przyznać, że to najbardziej zaawansowany system tego typu jaki istnieje. Wystarczy, że wrzucicie na swój kanał jakieś znane nagranie, kilka godzin i komunikat: ktoś rości sobie do niego prawo i albo je usuniesz albo pozwolisz nam na nim zarabiać. Jak Content ID w ogóle jest w stanie przeszukiwać miliardy godzin filmów i porównywać je z milionami różnych utworów? Oczywiście Google nie bierze informacji o prawach do nagrań z próżni – wykorzystuje informacje przesyłane przez swoich partnerów.

YouTube Content ID Handbook
YouTube Content ID Handbook
Schemat działania jest prosty: partner (np. wytwórnia muzyczna) przesyła do YouTube (z reguły za pomocą standardu DDEX) specjalny batch danych – assetów. W przypadku muzyki na asset składa się:
- Nagranie audio
- Metadane (czyli opis tego „co jest” w nagraniu – tytuł, wykonawcy, twórcy itp.)
- Informacje o prawach do kontentu (kto reprezentuje nagranie na danym terytorium)
- „Match politicy” – co YouTube ma „zrobić” jeśli jakiś użytkownik wrzuci film z danym nagraniem.
YouTube te wszystkie informacje zapisuje w swoich bazach danych, a dla nagranie generuje „accoustic fingerprint”, czyli „elektroniczny odcisk” piosenki. Kiedy użytkownik wrzuci swój film, YouTube generuje i dla niego taki odcisk, a następnie przeszukuje swoją bazę czy przypadkiem nie posiada już referencji z takim nagraniem. Jeśli tak – stosuje politykę, którą właściciel praw przekazał w zgłoszonym assecie.
Brzmi to bardzo ładnie, ale dla mnie opis „porównuje elektroniczne odciski nagrań” nie jest zbyt wyczerpujący. Z tego powodu zrobiłem mały research dowiadując się jak działają algorytmy accoustic fingerprintów systemów Content ID czy Shazam. Okazało się, że najpopularniejsza implementacja sprowadza się do generowania krótkich kluczy („hash”) i porównywanie ich ze sobą. Postanowiłem więc zaimplementować własny algorytm, żeby pokazać jak wygląda to w praktyce.
Hashowanie nagrania krok po kroku(implementacja MR)
1. Preprocessing audio
Etap preprocessingu polega na wstępnej, zazwyczaj bardzo prostej, „technicznej” obróbce nagrania – dotyczy to takich „pragmatycznych” czynności jak konwersja formatu, konwersja dźwięku stereo na mono czy zmiana częstotliwości próbkowania. Na tym etapie można implementować także algorytmy normalizacji i kompresji dźwięku czy też jego wstępnego odszumiania. W moim przypadku ten krok sprowadził się do konwersji plików MP3/M4A na wav (16 bit, 44,1 kHz).
2. Szybka transformata Fouriera
Jeśli choć trochę liznęliście teorii sygnałów (tak jak ja, bo mimo dwóch semestrów z takimi przedmiotami, nadal FFT jest dla mnie czarną magią) powinniście wiedzieć, że każdy sygnał można „rozłożyć” na czynniki pierwsze, czyli na składowe harmoniczne (czyli przejść z dziedziny czasu do częstotliwości). Taka operacja to tzw. transformacja Fouriera a jej realizacja dyskretna – szybka transformacja Fouriera (FFT) – w ogóle pozwala nam słuchać muzyki czy oglądać filmy.
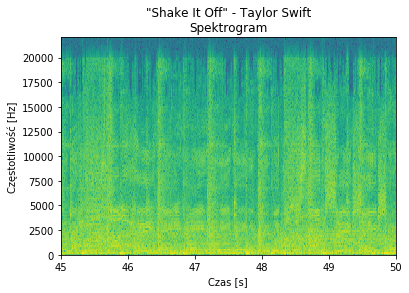
Całe szczęście implementację FFT posiada każde sensowne środowisko, (nawet Python, którym zainteresowałem się dwa tygodnie temu; dziwny język nawiasem mówiąc), więc moja praca programisty ograniczała się do 5 linijek. Efekt pracy jest następujący: z sygnału „czasowego” (waveform) wygenerowałem piękne spektrogramy badanych piosenek – w moim eksperymencie skupiłem się na „1989” Taylor Swift, a w szczególności na nagraniu „Shake It Off”:
3. Wyszukiwanie maksimów lokalnych
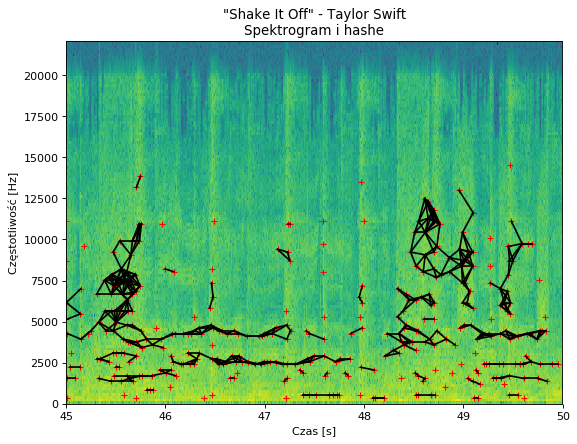
To co pojawia się charakterystycznego na spektrogramie to wyraźne pionowe i poziome paski – to one, a właściwie ich względne ustawienie niosą informację o muzyce. I co najzabawniejsze – nie ważne jak dźwięk jest zniekształcony i zaszumiony, ich ustawienie się nie zmienia (gdyby się zmieniło mielibyśmy po prostu utwór). I tu pojawia się sekret accoustic fingerprintingu – analiza rozkładu tych prążków.
W praktyce nie analizuje się jednak położenia samych prążków, a punktów charakterystycznych o największej amplitudzie – tzw. maksimów lokalnych. Tutaj zaczynają się schody – maksimów lokalnych na powyższym spektrogramie może być i kilka tysięcy i kilkanaście. Wszystko zależy od algorytmu, jaki zastosujemy (także od ustawień FFT z poprzedniego punktu). W przypadku ACR z pożądanych jest kilkadziesiąt do kilkuset punktów charakterystycznych na sekundę i z reguły generuje się ich więcej, ale wybiera się Top o największej intensywności.
W moim przypadku zdecydowałem się na uwzględnianie obszarów 64 próbkowych i wybieraniu Top75 ekstremów na sekundę w przedziale 250 Hz do 15 kHz. Wygląda to tak:
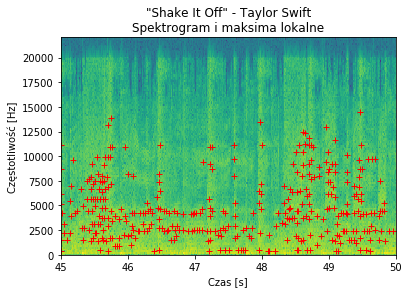
4. Grupowanie ekstremów w hashe
To co mnie zastanawiało najbardziej, to sposób w jaki można szybko porównywać miliony nagrań pod kątem ułożenia takich malutkich krzyżyków. Okazuje się, że ten problem jest tak prosty jak łączenie kropek… dosłownie. Sztuczka polega na łączeniu ekstremów w pary spełniające określone warunki. Algorytm wygląda następująco: dla każdego z ekstremów (a) znajdź wszystkie inne ekstrema (b), które spełniają warunek:
- Współrzędne czasowe: Ta < Tb < Ta + deltaT
- Współrzędne częstotliwościowe: Fa – deltaF <= Fb <= Fa + deltaF
W moim przypadku odległość „w czasie” punktów musiała być mniejsza niż 150 ms (ale nie zerowa!), a w dziedzinie częstotliwości mniejsza niż 1 półton. Po połączeniu takich punktów powstała bardzo ładna mapa hashy:
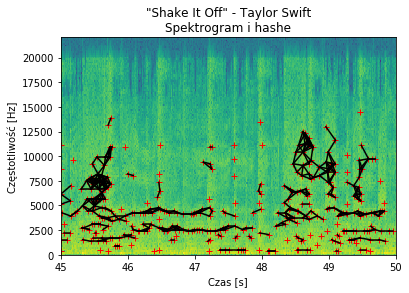
5. Zapis do bazy danych
W ten sposób dla każdego nagrania udało mi się wygenerować listę rekordów składających się z:
- Nazwy nagrania (klucz);
- Początek hasha (sekundy) – zaokrąglona do 2 miejsca po przecinku;
- Początek hasha log10 z częstotliwości w Hz – zaokrąglona do 2 miejsca po przecinku;
- Długość hasha w sekudnach – zaokrąglona do 2 miejsca po przecinku;
- Długość hasha w półtonach – zaokrąglona do 2 miejsca po przecinku;
Wszystkie rekordy zostały zapisane w bazie danych w dwóch tabelach: dla nagrań referencyjnych w tablicy „REF” i w „HASHES” dla badanych nagrań. Podejrzewam, że w tym przypadku sprawdzają się najlepiej nierelacyjne bazy danych typu „key-value”, ale na moje potrzeby wydajność operacji była najmniej ważna.
6. Porównywanie rekordów
Po tych wszystkich operacjach wyszukiwanie nagrania podobnego sprowadza się do zapytania SQL i znalezienia wspólnych hashów – w nagraniu badanym i w nagraniach referencyjnych (Inner Join). Tak znalezione rekordy referencyjne sprawdza się pod kątem ich sekwencji w czasie – czy hashe które występują po sobie w badanym nagraniu są „po kolei” w nagraniu potencjalnie referencyjnym, czy może ich wystąpienie to zwykły przypadek. Najprościej (i najszybciej) zbadać to histogramem o czym poniżej.
Testy
I teraz najważniejsze – czy moja implementacja algorytmu zadziałała? O dziwo… tak! Do testów wybrałem piosenkę „Shake It Off” oraz „Welcome to New York” jako referencje oraz „Shake It Off” jako badane nagranie w kilku wersjach. (PS. Proszę mnie nie zgłaszać do ZAiKS – nagrania umieszczam w celach edukacyjnych!!!)
I. Nagranie streamu audio z YouTube (sygnał skompresowany)
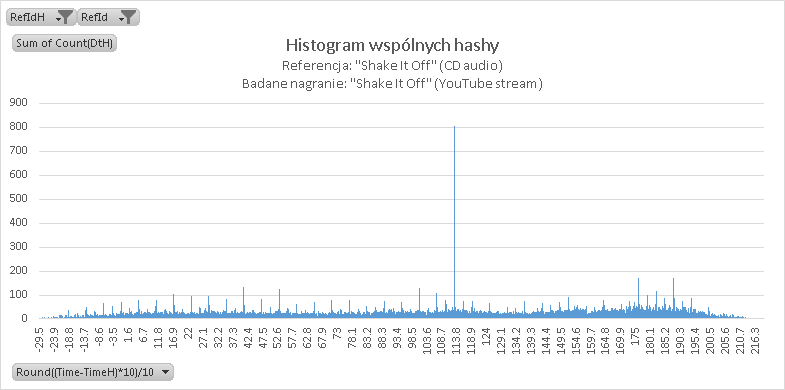
Wynik jest doskonały – na histogramie widoczny jest silny pik o wartości 112,9 sekundy – oznacza to, że początek mojego badanego nagrania zaczynał się dokładnie w 113 sekundzie. Dla porównania tak wygląda histogram audio „Shake It Off” względem referencji „Welcome to New York” – wyraźnego prążka brak…
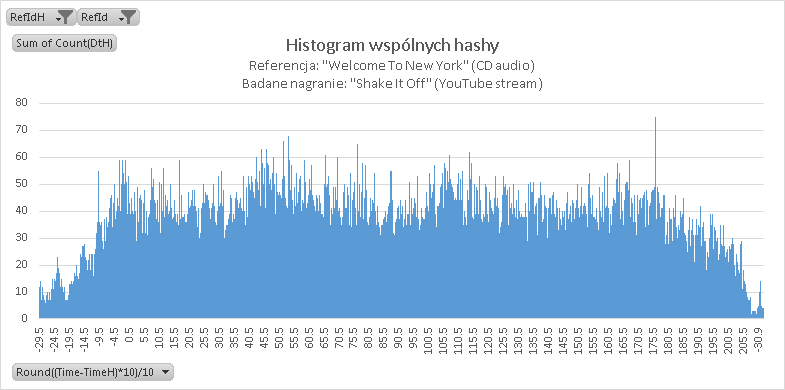
II. Nagranie streamu audio z YouTube za pomocą smartfona (low quality) [32 sekundy]
Popularny Shazam potrafi nie tylko rozpoznać piosenkę w jakości studyjnej – całkiem dobrze wyszukuje on oryginały w oparciu o słabej jakości nagrania. Taki plik tekstowy przygotowałem i ja:
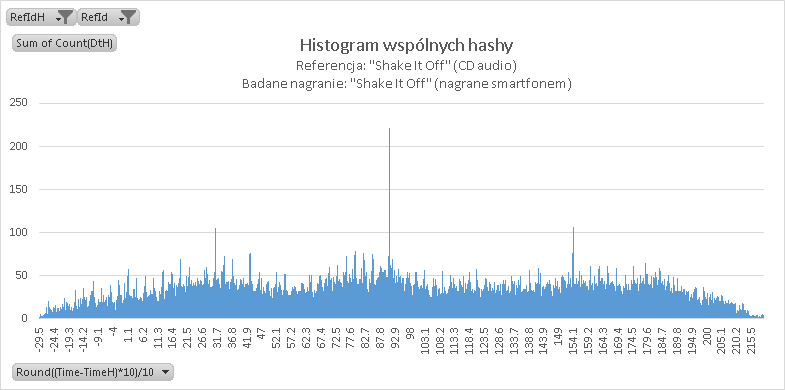
Wynik o dziwo… pozytywny. Wyraźnie widoczny jest prążek 90,9 s, co znaczy, że zacząłem zgrywać piosenkę w 1:31. Widoczne są też dwa mniejsze prążki – 30,9 s i 153,9 s związane z powtarzającym się refrenem po pierwszej zwrotce i bridge’u.
III. Instrumental [31 sekund]
Czy mając finalny miks w referencjach można rozpoznać piosenkę po warstwie instrumentalnej? Sprawdzamy:
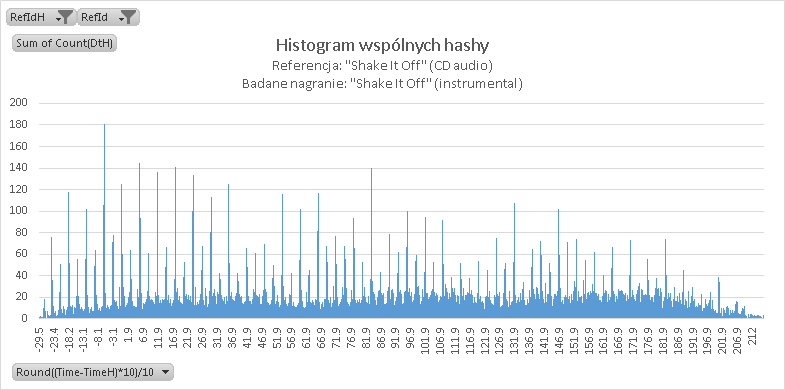
Odpowiedź brzmi: częściowo tak. Widoczne są regularne wyraźne prążki, a związane jest to powtarzalnością beatu piosenki. Tak więc wygląda na to, że przynajmniej w przypadku muzyki pop jest możliwość oznaczenia nagrania jako „potencjalnie podobne”.
IV. Wokale
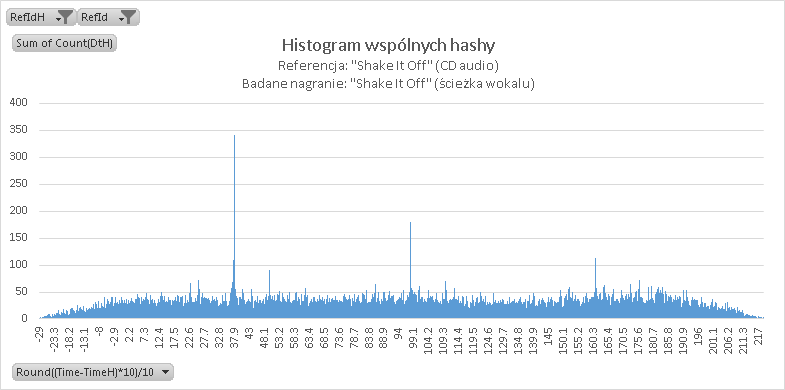
Tutaj rewelacji się nie spodziewałem a tu niespodzianka! Jak się okazuje algorytm lepiej rozpoznaje czysty wokal na podstawie miksu niż instrumental!
V Wersja live
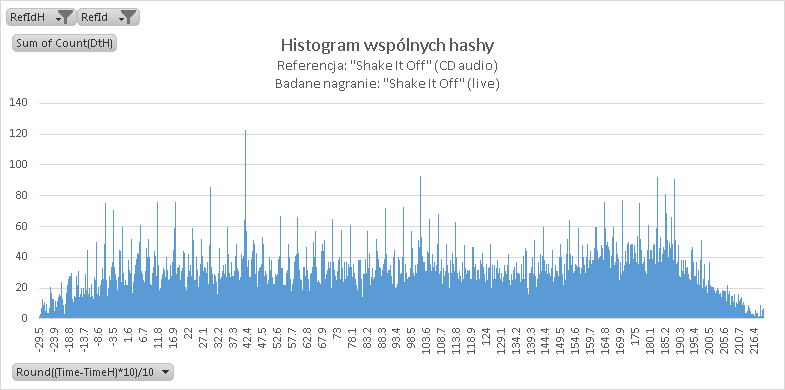
Moim zdaniem wynik na granicy błędu – podobnie jak w przypadku instrumentala widać jakąś zależność (pojawia się nawet wyraźny prążek), ale myślę, że ustalenie uniwersalnego progu dyskryminacji jest tutaj niewykonalne.
VI. Bonus – cover Megan Nicole (słuchacie na własną odpowiedzialność)

Wynik zbliżony do wersji instrumentanej – wiele prążków bez wyraźnego piku. Moim zdaniem w praktyce algorytm nie ma szans, aby prawidłowo rozpoznał takie nagranie, w szczególności przy zmianie tonacji.
Wnioski
Algorytmy accoustic fingerprinting oparte na mapach rozkładów lokalnych maksimów sprawdzają się bardzo dobrze zarówno w przypadku nagrań wysokiej jak i niskiej jakości. Są wstanie wykrywać zarówno finalny misk jak i wskazać podobieństwo dla poszczególnych warstw (wokal). W przypadku wersji koncertowych czy coverów teoretycznie jest możliwość wskazania podobieństw, jednak wygenerowałoby to zapewne zbyt dużo rozpoznać fałszywie pozytywnych. Zresztą jestem przekonany że te same progi dyskryminacji, które świetnie działają w przypadku muzyki popularnej, będą generowały liczne fałszywe rozpoznania w przypadku muzyki klasycznej (o mniej rozbudowanym widmie harmonicznym).
Niewydolność systemu w przypadku alternatywnych wersji oznacza to, że automatyczne zarządzanie prawami twórców (kompozytorzy, tekściarze) w serwisach user generated content jest tak naprawdę uzależnione od efektywności pracy producentów fonogramów. Ci muszą jak najbardziej rzetelnie przesyłać referencje do systemów takich jak Content ID, BMAT czy polskiego MicroBe – przede wszystkim jakość metadanych przesyłanych wraz z nagraniami musi być najbliższa temu co „widzą” stowarzyszenia takie jak ZAiKS. A niestety wiem z doświadczenia, że jest pod tym względem różnie. Na horyzoncie widać co prawda nową technologię, ale do jej efektywnej implementacji droga jest bardzo daleka…
P.S Zainteresowani kodem źródłowym (roboczy) mogą go pobrać stąd: https://pastebin.com/Ff9PHNbn